计算机网络代写 IP addresses代写 Internet代写 CS代写
1114CSCI-UA.0480-009 midterm (47 points) 计算机网络代写 1. (3 points) What are the units of throughput, queueing delay, window size, capacity, RTT, and Bandwidth-Delay Product? Instructi...
View detailsSearch the whole station
并行计算考试代考 Important Notes- READ BEFORE SOLVING THE EXAM • If you perceive any ambiguity in any of the questions, state your assumptions clearly and
• If you perceive any ambiguity in any of the questions, state your assumptions clearly and solve the problem based on your assumptions. We will grade both your solutions and your assumptions.
• This exam is take-home.
• You are allowed only one submission, unlike assignments and labs.
• Your answers must be very focused. You may be penalized for wrong answers and for putting irrelevant information in your answers.
• Your answer sheet must have a cover page (as indicated below) and one problem answer per page. This exam has 6 problems.
• The very first page of your answer must contain:
– You Last Name
– Your First Name
– Your NetID
– Copy and paste the honor code showed in the rectangle at the bottom of this page.
• You may use the textbook, slides, and any notes you have. But you may not use the internet.
• You may NOT use communication tools to collaborate with other humans. This includes but is not limited to G-Chat, Messenger, E-mail, etc.
• Do not try to search for answers on the internet it will show in your answer and you will earn an immediate grade of 0.
• Anyone found sharing answers or communicating with another student during the exam period will earn an immediate grade of 0.
• “I understand the ground rules and agree to abide by them. I will not share answers or assist another student during this exam, nor will I seek assistance from another student or attempt to view their answers.”
Assume we have the following task flow graph where every node is a task and an arrow from a task to another means dependencies. For example, task B cannot start before task A is done.
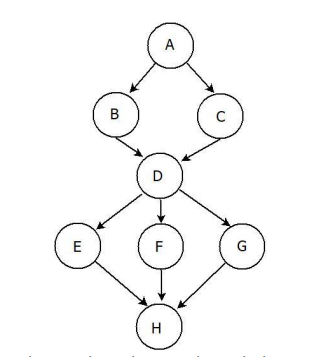
The following table shows the time taken by each task in nano seconds.
| Task | Time Taken |
| A | 50 |
| B | 10 |
| C | 10 |
| D | 5 |
| E | 10 |
| F | 100 |
| G | 10 |
| H | 100 |
a. [4 points] What is the minimum number of cores needed to get the highest performance? What is the speedup given the number of cores you calculated?
b. [4 points] What is the span? What is the work?
c. [4 points] Given what you calculated in (b) above, what is the parallelism? And what does the parallelism number you calculated mean?
d. [4 points] Is the number you calculated in (c) different than the number of you calculated in (a)? Justify.
e. [4 points] Do you think we can have a loop in the task graph above (i.e. an arrow pointing to an earlier task)? If no, how can iterations be represented? If yes, how will you calculate the span in that case?
f. [4 points] Suppose we have two scenarios: In one of them we have x cores and in the other we have y cores. Choose x and y such that x cores gives you lower speedup but higher efficiency for the graph above. than y cores? Is it possible to do that? If yes, please given an example using the above graph (and calculate both the speedup and efficiency). If not, explain in 1-2 sentences why not.
Answer the following questions about technology and hardware design.
a. [4 points] What is the importance of Moore’s law that is related to multicore processors?
b. [4 points] Why it is not easy to just write a sequential program and let the compiler generate the parallel version of it? You answer must not exceed two sentences.
c. [4 points] We say that in hardware pipelining, with five stages (fetch, decode, issue, execute, commit), the hardware can execute several instructions at the same time but each instruction is in different phase of its lifetime. That is, one instruction in its fetch phase, another in its decode phase, a third in the issue phase, etc. So, if we increase the number of stages from five, as we saw in class, to ten, does this guarantee we will have ten instructions being executed in parallel most of the time? Why? or Why not?
d. [4 points] Since MIMD can implement all the other types (SISD, SIMD, and MISD). Then why did we build chips based on SIMD (like GPUs) and did not build all chips as MIMD?
e. [4 points] We saw four different categories of architecture in Flynn’s taxonomy. What is the classification of single core with speculative execution and superscalar capability? Justify your choice.
f. [4 points] As the number of cores increases, cache coherence protocols are implemented as directory-based and not snoopy, why is that (in 1-2 sentences)?
Answer the following questions regarding parallel programming techniques.
a. [5 points] State five reasons, each one not exceeding two sentences, about why it is almost impossible to eliminate load imbalance in parallel programs.
b. [4 points] Why is it good to start by writing a sequential code of the problem to be solved then parallelize that code? State one reason in 1-2 sentences.
c. [10 points] For each one of the following problems, choose whether you will parallelize it using task-level, or divide and conquer. Then add 1-2 sentences justifying your choice.
| Problem | Task level or divide and conquer | Justification |
| matrix multiplication | ||
| factorial n | ||
| matrix transpose | ||
| matrix addition | ||
| find all even numbers in a list |
[4 points] Suppose we have the following two pieces of code.
| …. x = TRUE; …. | … if(!x) x = TRUE; …. |
A program wants to decide whether to use the code on the left or the code on the right in a multithreaded program. It is obvious that both are doing the same thing. Which one do you think has the potential of being faster? and why? (Not giving a justification will not earn you any credit).
[9 points]
Suppose we have a quad-core processor. Each core has its own L1 cache. There is a shared L2 cache. The block size for all caches is 32 bytes in size. We have an array of 256 integers. We want to increment each element of that list by one. We want to do that by writing a multithreaded program. The elements of this array will be divided among the four cores. State which elements of that array will be assigned to which core to reduce the possibility of false sharing and ensure load balancing, in each one of the following scenarios. Also, for each one, give one sentence justification:
a. Each L1 cache is 64KB of size and is 2-way set associative.
b. Each L1 cache is 32KB of size and is 4-way set associative.
c. Each L1 cache is 16KB and is 8-way set associate.
Answer the following questions regarding MPI.
a. [4 points] If we run MPI on a shared memory machine, do we risk suffering from coherence? Justify in 1-2 sentences.
b. [4 points] In 1-2 sentences explain why MPI gives each process a rank?
c. [4 points] We saw the API MPI_Comm_size() that gives the total number of processes. But, we already specify the number of processes when we write execution command. Then, why do we need such an API? State two reasons.
d. [4 points] What is the reason for having something called communicator in MPI?
e. [4 points] Most collective calls in MPI have either a field for source process or a field for destination process, but never both. Why is that? State your reason in 1-2 sentences.

更多代写:美国CS网课代修多少钱 多邻国线上考试 英国商业剖析代写 人类学论文代写 商科论文范围 留学英文论文代写
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

CSCI-UA.0480-009 midterm (47 points) 计算机网络代写 1. (3 points) What are the units of throughput, queueing delay, window size, capacity, RTT, and Bandwidth-Delay Product? Instructi...
View details
CS 2100: Discrete Structures Homework 7 离散结构代写 Section 5.1 1. Exercise 3.d on page 515. Refer to the graph G2 below. Construct a second graph H with the same number of nodes and ed...
View details
CS 188 Introduction to Artificial Intelligence hw1 人工智能作业代写 Q1 Search Trees 4 Points How many nodes are in the complete search tree for the given state space graph? The start state ...
View details
Parallel Computing Homework Assignment 1 并行计算家庭作业代写 1.In the global sum problem that we discussed in class, in lecture 1, if we assume that there is a variable called my_rank (loca...
View details