统计学的基本概念代写 统计学代写 统计考试代考 统计代做
596Practice Midterm 统计学的基本概念代写 Part I. Points and Number within sections are approximate and may change. Short Answers –2 points each (5) 1.Will we get nominal or ordinal data Part I...
View detailsSearch the whole station
数据分析课业代写 When an assignment involves working with data or/or coding, you do not need to submit the data or the code that you used to solve the assignment.
The attached Excel spreadsheet, “Price of a Big Mac in U.S. over time.xlsx,” contains monthly time-series data on the nominal price of a Big Mac (the sandwich from McDonald’s) over time in U.S. dollars. The sources of the data are listed immediately on top of the data (within the spreadsheet).
Although this is monthly data, please note that certain months are missing. This is simply a fact of these data. Very rarely we have the luxury of working with a perfectly balanced data, particularly when there is a time dimension to the data, and this particular data is no exception to this fact.
Using the “CPI-U, all items, non-seasonally adjusted” monthly series (i.e., CPI for urban consumers that includes all items), which you can obtain from the Bureau of Labor Statistics (BLS), please convert this nominal price time-series to a “real” price time-series (i.e., an inflation-adjusted series). Next, please plot both the nominal and the real time-series within one single chart. Finally, please write a brief write-up on your findings, For example, when were Big Mac’s the most vs the least expensive, in real terms? Were you surprised by any of the results? Do you observe any specific interesting trends and patterns in the data? Etc.
Please note that when constructing a “real” time-series of prices, one wants to inflation-adjust each nominal price to the most recent time period available within the data.
Finally, please make sure that you follow the “do’s” and “don’t’s” of charting, because points will be deducted if those guidelines are not followed.
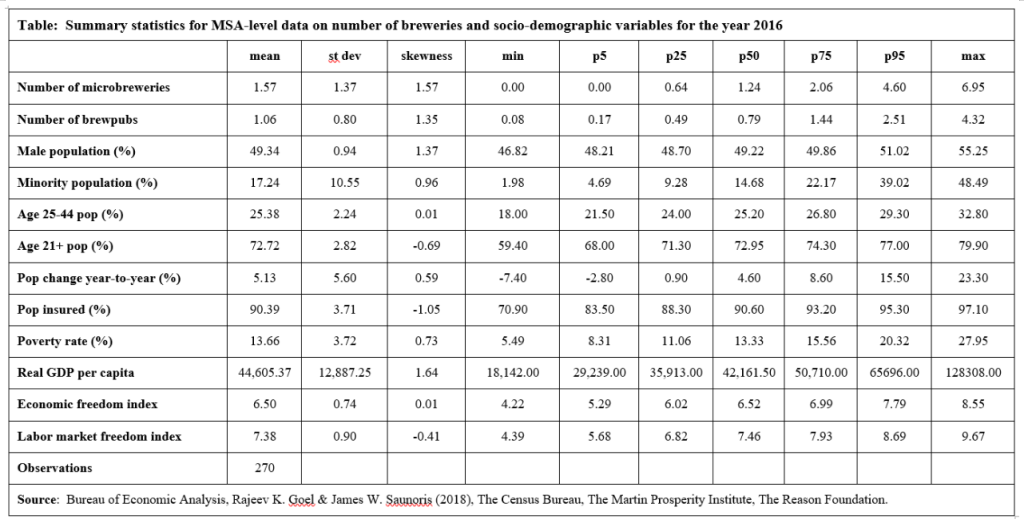
One of the most important aspects of analyzing data is the ability to summarize it efficiently. An important tool that allows us to summarize data efficiently is a table of descriptive statistics. This type of table displays, within one single page, some key statistics such as average, standard deviation, skew, min, max, and percentiles for each of the variables within a dataset. Below is an example of such a table, which summarizes a dataset on 270 MSAs (Metropolitan Statistical Areas) across the U.S. That table takes the original dataset, which is at the MSA-level, and provides statistics on the share of the insured population across the MSAs, on real GDP per capita across the MSAs, on the number of microbreweries across the MSAs, and on several other variables. (Please note that the “p”s represent percentiles; for example, “p5” is fifth percentile.) 数据分析课业代写
This question asks you to create a table of descriptive statistics for a different dataset. Specifically, attached to this assignment is a cross-sectional dataset, called “County-level dataset.xlsx,” that contains information at the county level for the year 2012. For each county in the U.S., it contains data on, for example, the percentage of the population that is obese, median income, the number of fast-food restaurants per 100,000 people, the share of the population that is Hispanic, the percentage of the population that has a high school diploma or higher, and so on. This data was compiled from the following sources:
Please use a statistical software (R, Excel Stata, Python, etc) to create a table of descriptive statistics for this dataset. Please follow the format of the table that is displayed below, because in economics that is the typically used format. In other words, your table should have an informative title, should fit within one single page (and not spillover across multiple pages), should have a footnote, the description of the variables should be in the first column and be self-explanatory, the names of the statistics should be on top (as a row), the table should be as clutter-free as possible (for example, there is no need to display more than two decimal numbers for each number), it should be typo-free and with no grammatical errors, its columns should be aligned, etc.
In other words, the “look” of the table matters, and its look will be reflected on the grade that you receive.
From directly inspecting the table that you just created, and directly using the numbers in the table (and not in the raw data), please answer the following:
i. Which variables (if any) are moderately skewed right? Please explain why.
ii. Which variables (if any) are strongly skewed left? Please explain why.
iii. Which variables (if any) have “extreme” outliers on the right? Please explain and show your calculations.
iv. Suppose there is a particular county whose obesity rate is 19.7%. What is the z-score of this county for obesity rate?
v. Your friend tells you that 45% of the observations for median income fall within the range of $43,039 and $65,799. Is your friend correct? Please explain.
vi. Please note that, for certain variables, the mean is meaningfully larger (say, more than 50% larger) than the median. Please explain, making reference to one of the statistics displayed in the table, why that is the case.

更多代写:CS加拿大线上代考 gmat线上考试作弊 英国微积分代考 心理学研究论文代写 北美研究paper代写 美国大学抄袭
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

Practice Midterm 统计学的基本概念代写 Part I. Points and Number within sections are approximate and may change. Short Answers –2 points each (5) 1.Will we get nominal or ordinal data Part I...
View details
data analysis代写的正确打开方式,告别为计算机作业天天熬夜! data analysis代写 近年来我国兴起了一股留学潮,家长们纷纷在条件和实力允许的情况下把孩子送到国外去留学,在锻炼他们独立生存能力的同时,...
View details
STAT 404 - Assignment 4 Total marks: 45 + 1 bonus 代做留学统计作业 The data set in the file PaperHelicopter.txt was contributed by a volunteer student (one of you). Two factors are consider...
View details
STA4003 Project 统计数据分析代写 The submitted codes must be clearly written in a R file with an output MSE. A report to describe your analysis is required. The submitted codes must ...
View details