物理攻击与对策代写 CS579/ECE599代写 算法代写 Python代写
597CS579/ECE599 Assignment Homework 1 物理攻击与对策代写 Please complete this assignment (100 pts total) and submit your report/program code on Canvas (all files compressed in one .zip witho...
View detailsSearch the whole station
CS考试代考 Read the following: • RIGHT NOW! Write your name, student ID and section number on the top of your exam. If you’re handwriting your exam,
• RIGHT NOW! Write your name, student ID and section number on the top of your exam. If you’re handwriting your exam, include this information at the top of the first page!
• You may use the textbook, your notes, lecture materials, and Piazza as resources. Piazza posts should not be about exact exam questions, but you may ask for technical clarifications and ask for help on review/past exam questions that might help you. You may not use external sources from the internet or collaborate with your peers.
• You may use a calculator or Python terminal to check numerical results.
• If you print a copy of the exam, clearly mark answers to multiple choice questions in the provided answer box. If you type or hand-write your exam answers, write each problem on their own line, clearly indicating both the problem number and answer letter.
• Mark only one answer for multiple choice questions. If you think two answers are correct, mark the answer that best answers the question. No justification is required for multiple choice questions. For handwriting multiple choice answers, clearly mark both the number of the problem and your answer for each and every problem.
• For free response questions you must clearly justify all conclusions to receive full credit. A correct answer with no supporting work will receive no credit.
• When submitting your exam to Gradescope, use their submission tool to mark on which pages you answered specific questions. Submitting your exam properly is worth 1/100 points. The other problems sum to 99.
Which of the following tests are appropriate for the goal of establishing uncertainty or confidence intervals on the interquartile range of a probability process?
A. Because of the central limit theorem, we can use normals for any problem like this.
B. For small samples, we can create a confidence interval on teh interquartile range via t-distributions.
C. We could simulate the probability process and bootstrap to find confidence intervals for an interquartile range.
D. None of the above will work: we’d have to use exact sums or integrals of the probability process to get theoretically consistent estimates.
You are sampling the weights of various puppies from a population with a known mean of 15 pounds and variance of 16 pounds2 . You obtain a measurement from an adorable Beagle of X = 19 pounds. What is the corresponding value of the standardized normal random variable, Z?
A. 0.25
B. 0.5
C. 1
D. 19/16
E. 2
F. 19/4
G. 15

A. A t– distribution is appropriate here, a standard normal is not.
B. A standard normal distribution is appropriate here, a t is not.
C. Neither a t not a standard normal is appropriate.
D. Either a t or a standard normal is suitable for this problem.
A random variable U has a standard deviation equal to sU , and a random variable V has a standard deviation equal to sV . U and V are independent. Let W = U + V . What is the standard deviation of W?

You’re performing a simple linear regression, and someone spills ink all over your beautiful regression table. Now you can only read the following, though you also do recall that the data set had 147 observations, and most of their x-values were close to x = 1:
| Coefficient | Estimate | Std. error | t-value | Pval |
| (Intercept)Slope | 3.45.56 | MISSING0.19 | 3.1MISSING | MISSING< 2e-16 |
What is the correct (exact) MISSING value for the intercept’s p-value?
A. stats.t.ppf(3.1, df=147)
B. 2(1-stats.t.cdf(3.1, df=145))
C. 3.4 · 3.1
D. 2(1-stats.t.cdf(3.1, df=147))
E. (1-stats.norm.cdf(3.1))
From the same table as the prior question, what is the (exact) MISSING value for the t-value of the slope?
A. 5.56/0.19
B. stats.t.ppf(5.56)- stats.t.ppf(0.19)
C. stats.t.ppf(5.56, df=145)- stats.t.ppf(0.19, df=145)
D. stats.norm.ppf(2e-16)
E. 5.56 · 0.19
Suppose we were to take this linear regression and add in an additional predictor of x2 , so the model became y = β0 + β1x + β2x2 + ε. Which of the following best describes all of the results of this added parameter?
A. The R2 of the model will increase.
B. The standard error associated with β1 will increase.
C. Because the coefficient for β1 was so significant, it’s unlikely that adding x2 will help the model.
D. Only (A) and (B) are true.
E. Only (A) and (C) are true.
F. Only (B) and (C) are true.
G. All of (A), (B), and (C) are true.
Suppose we found ourselves a new data value at the (x, y) location of (12, 50). What would be the effects of this data point on the resulting line of best fit?
A. The estimate for β1 will increase.
B. The standard error associated with β1 will increase.
C. The total SSE of the model will decrease.
D. Only (A) and (B) are true.
E. Only (A) and (C) are true.
F. Only (B) and (C) are true.
G. All of (A), (B), and (C) are true.
Suppose you compute a sample mean for a population that is normally distributed with known variance σ2 . Which combination of significance level and sample size n produces the narrowest confidence interval for the mean?
A. α = 0.2 and n = 50
B. α = 0.2 and n = 12
C. α = 0.01 and n = 50
D. α = 0.01 and n = 12
E. α = 0.04 and n = 50
F. α = 0.04 and n = 12
Data Scientists are often involved in study planning. You are in charge of a study that examines the mean lifetime (in years) of different cars. You know that the standard deviation of the lifetime of cars is σ = 1.2 years. What value of n do you need for the maximum 95% confidence interval width to be at most 0.5 years?
A. 9
B. 10
C. 22
D. 23
E. 30
F. 88
G. 89
H. 100
I. 101
J. 1000
Which of the following statements is True?
A. You cannot make a Type I error when the null hypothesis is false.
B. You cannot make a Type II error when the null hypothesis is false.
C. The test that minimizes Type I error rate α will also be the one that minimizes the Type II error rate β.
D. The p-value is the probability that the null hypothesis is true.
E. The larger the p-value, the more we doubt the null hypothesis.
Consider performing a multiple linear regression on a data-set with full and reduced models of the form y = β0 + β1x1 + β2x2 + β3x3 + β4x4 and y = β0 + β1x1 + β4x4, respectively. Suppose that you perform a partial F test and reject the null hypothesis. What is the strongest conclusion you can draw?
A. Nothing.
B. βk ≠ 0 for some k ∈ {2, 3}.
C. βk = 0 for all k ∈ {1, 2, 3, 4}.
D. βk ≠ 0 for all k ∈ {2, 3}.
E. β1 = β4 = 0.
F. β2 = β3 = 0.
G. The model with β1 = β4 ≠ 0 is not significantly better at capturing variance than the model with β1 = β4 = 0
Suppose you generate 5,000 confidence intervals for the mean of a population, using fixed significance level α. You discover that 491 of them FAIL to cover the true mean. Which of the following is the most appropriate estimate of the significance level α?
A. 0.01
B. 0.025
C. 0.05
D. 0.1
E. 0.2
F. It’s 50-50.
G. 4509/5000
Answer the following short answer prompts after each question.
What is the difference in how we interpret the pdf f(x) of a continuous random variable and the pmf f(x) of a discrete random variable? Do they have the same units? What does each measure?
Suppose that a sample X1, X2, . . . X65 comes from a population with an unknown distribution. The population has a mean of 42 and a standard deviation of 12. Find the probability that the sample mean is between 40 and 47. Write your answer three ways: in critical value notation (using e.g. tα,ν, zα2 ) and with exactly how you would find those values using python code (using scipy.stats syntax:.ppf, .cdf, .pdf, etc.) and the exact interval. Is this answer exact or an approximation? Why or why not?
Suppose we’re constructing a linear model to test the reaction of COVID vaccines, and suspect their may be a difference based on the sex of the recipient. We decide on the model:
yi = β0 + β1 · Wi + β2 · Mi + εi
where yi is the strength of response of patient i, Wi is that patient’s weight in pounds, and Mi is an indicator or dummy variable that is true when the patient is a Male. We gather some data, and the first 6 patients are {(165, M),(125, W),(220, M),(145, M),(150, W),(185, W)}. What are the first 6 rows of the corresponding design matrix?
You have 12 observations drawn from a normal distribution with unknown parameters, and want to test the hypothesis Ho : µ = µ0 vs. Ha : µ > µ0. You will reject the null hypothesis if your test statistic is greater than 1.84. What is the probability of a Type I error for your test? Write your answer both in critical value notation (using e.g. tα,ν, zα2 ) and with exactly how you would find those values using python code (using scipy.stats syntax:.ppf, .cdf, .pdf, etc.) and the exact probability.
An e-commerce client claims that more than 20 percent of visitors to their site eventually become buyers (tracked by a cookie). Test this claim if a random check of the web server log indicates that 54 of 200 visitors made a purchase from the web site. In testing this claim, follow these four steps:
1. (5 points) Construct and interpret the 95% confidence interval for the true proportion of customers who become buyers.
2. (2 points) Write down the two hypotheses being tested, and define any parameter used in the hypotheses.
3. (5 points) Calculate the appropriate test statistic and its corresponding p-value.
4. (2 points) Using the p-value, decide whether or not to reject the null hypothesis at the 1% significance level and interpret your conclusion in terms of the original problem.
It’s line-drawing time! The next 4 questions refer to the following plot, with fitted least-squares line by model Yi = β0 + β1Xi + εi shown:
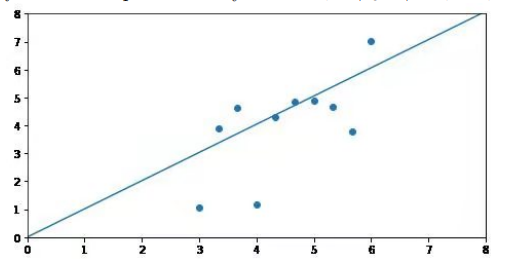
Note that the fitted line goes through exactly (0,0), here. The above plot was created by running slr=sm.OLS(x,y).fit() on a pair of numpy arrays holding the x and y coordinates of the data. For questions (a), (b), and (c), if the statement is always true mark “True”; if it is possible for the statement to be false, mark “False.” You need to justify your answer with (at least) a full sentence:


更多代写:亚特兰大CS网课代上 在家考gre作弊 英国牙科学作业代写 医药学Medicine论文代写 艺术类Assignment代写范文 essay格式代写
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

CS579/ECE599 Assignment Homework 1 物理攻击与对策代写 Please complete this assignment (100 pts total) and submit your report/program code on Canvas (all files compressed in one .zip witho...
View details
python code代写会不会是直接抄袭的其他源代码?怎么检验? python code代写 计算机程序的学习非常有用,能够做很多的工作,比如软件工程师、网络安全工程师等,国外的计算机行业也非常发达,去国外高校深造...
View details
CPSC111-Introduction to computing 计算概论代写 Assignment 2 – Python Practice: working with functions & Turtles As always, all your answers should use functions and every function should...
View details
The Problem Python语言设计代写 In this assignment you will write an interpreter in Python for a simplified PostScript-like language, concentrating on key computational In this assignment y...
View details