r语言代写-r语言考试和作业难度大吗?不会可以找r语言代写
904r语言考试和作业难度大吗?不会可以找r语言代写公司帮做吗? r语言代写 在国外留学生可以获得更好的教学条件和资源,并且掌握世界一线知识和技巧,特别是互联网行业。现在很多国外大学都纷纷开设相关专业供留...
View detailsSearch the whole station
金融大数据分析代写 Summarizing Data on Firm Fundamentals The file firm.csv containsfirm fundamental variables, including total assets, net income,
The file firm.csv containsfirm fundamental variables, including total assets, net income, and cash dividends, regarding 8 firms during fiscal years of 2015 to 2018.
In this lab assignment, we will explore data using the five dplyr functions: filter, arrange, select, mutate, and summarize.
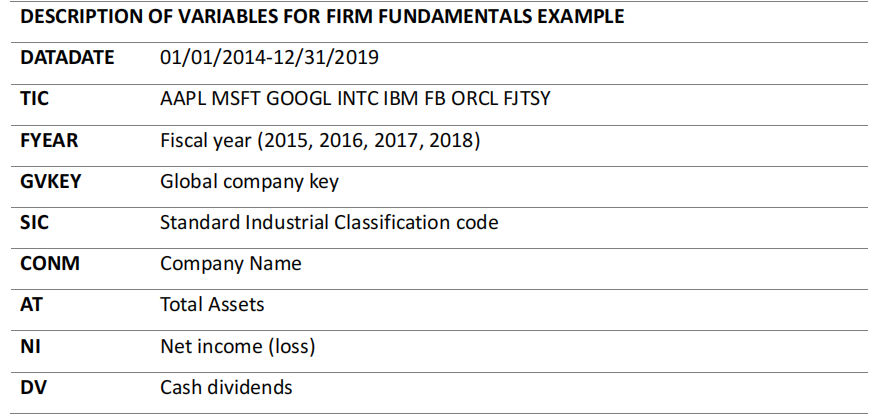
Use library() to load tidyverse.
Load the data using read_csv() and save the result in a tibble named df. Return the first six rows and column names using head() and names(), respectively.
2.1) average net income
Compute the average net income (NI) using mean().
2.2) first decile of net income
Find a value of net income such that 10% net income values are less than it and 90% are greater than it using quantile().
2.3) summary of net income
Calculate the minimum, the first quartile, the median, the mean, the third quartile, and the maximum value of net income using summary().
3.1) number of rows
Count the number of observations that have dividends (DV) greater than 0 and net income (NI) greater than 10000 using sum().
3.1) proportion of rows
Find the proportion of observations that have dividends (DV) greater than 0 and net income (NI) greater than 10000 using mean().
4.1) average and maximum net income
Calculate the average value and the maximum value of net income, the number of observations, and the number of unique TIC values using summarize(). Specify the names of the summary statistics as NI_mean, NI_max, n_rows, and n_firms, respectively.
4.2) average and minimum net income by firm
Group df by TIC and save the grouped data as df_by_TIC using group_by().
Calculate the average value and the minimum value of net income by TIC, and the number of observations in each group using summarize(). Specify the names of the summary statistics as NI_mean, NI_min, and n_rows, respectively.
5.1) average net income by firm
Group df by TIC, calculate average net income and save it as NI_mean, and arrange the result in a descending order of NI_mean.
5.2) most recent return on assets by firm
Create a new variable named ROA, group df by TIC, order the result in a descending order of FYEAR, keep the first observation in each group, and name it as recent_ROA.
Hint: return on assets (ROA) is defined as the ratio of net income (NI) by total assets (AT).
The file manager.csv contains executives’ compensation information regarding 7 firms during fiscal years of 2015 to 2018. We used this data set in lecture 3.
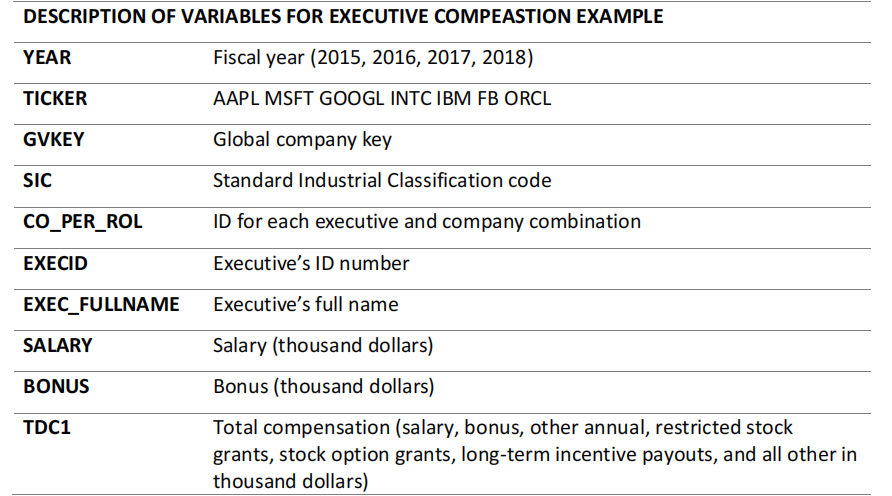
Load the data using read_csv() and save the result in a tibble named manager. Return the first six rows and column names using head() and names(), respectively.
Return frequency counts of unique TIC values in df using table().
Return frequency counts of unique TICKER values in manager using table().
Do these data sets cover same firms?
Return frequency counts of unique FYEAR values in df using table().
Return frequency counts of unique YEAR values in manager using table().
Do these data sets cover same fiscal years?
In this question, we will match the two data sets based on firm and year. In the merged data set, each row includes both executives’ compensation information (e.g., salary, bonus, total compensation), as well as firm fundamentals (e.g., net income, total assets, dividends).
Use inner_join() to return only matching rows from manager and df based on firm and year.
Inside inner_join(), specify manager, df, and the join criteria. Notice that firm and year have different names in manager and df. Save the resulting tibble as merged.
Hint: by = c(“TICKER”=”TIC”,”YEAR”=”FYEAR”) matches TICKER from manager with TIC from df, and YEAR from manager with FYEAR from df.
Return the first six rows and column names of merged using head() and names(), respectively.
Notice that the TICKER column stores firm tickers, the YEAR column stores fiscal years, and TIC and FYEAR columns are no longer listed.
Combine the following operations with the pipe:
– Select rows with YEAR=2017 or 2018 from merged using filter().
– Create a new variable named ROA in merged, which divides net income (NI) by total assets (AT).
– Group the data by TICKER using group_by().
– Using summarize(), calculate average SALARY and average ROA, and count the number of rows in each group. Specify the names of the summary statistics as SALARY_mean, ROA_mean, and n_rows, respectively.
– Order the result in a descending order of ROA_mean using arrange().

更多代写:C#线上考试怎么作弊 雅思indicator作弊 英国大学代做功课价钱 summary格式 project report写作建议 代考计量经济
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

r语言考试和作业难度大吗?不会可以找r语言代写公司帮做吗? r语言代写 在国外留学生可以获得更好的教学条件和资源,并且掌握世界一线知识和技巧,特别是互联网行业。现在很多国外大学都纷纷开设相关专业供留...
View details
ECON7310: Elements of Econometrics 计量经济作业代写 Instruction Answer all questions following a similar format of the answers to your tutorial questions. When you use R to conduct empirical ...
View details
STAT 6227, Assignment #1 数据统计作业代写 1. Distribution functions and hazard functions: Let T ∈ T be a time-to-event random variable within the time range T on (0, ∞) with probability 1. ...
View details
HW3 R作业代写 1.There is a raging debate among King’s undergraduate students about whether at the end of the first year. BSc Electronic Engineering (EE) students 1. There is a raging deba...
View details