算法分析代写 Analysis of Algorithms代写 Practice Exam代写
1281CSCI-570 Analysis of Algorithms Practice Exam - 2 算法分析代写 True/False Problems 1. For every graph G and every maximum flow on G, there always exists an edge such that increasing the ...
View detailsSearch the whole station
计算机体系结构cs代写 (1) In the textbook and lecture slides, detailed information in the pipeline registers (IF/ID, ID/EX, EX/MEM, MEM/WB) is not provided.
(1) In the textbook and lecture slides, detailed information in the pipeline registers (IF/ID, ID/EX, EX/MEM, MEM/WB) is not provided. Actually, each pipeline register can be divided into several fields. For “EX/MEM” pipeline register, give a name to each field, show the bit-width of it, and explain the role of it (including the fields for each control signal). Suppose the datapath/organization follows Figure 4.51 in Lec5_e.pdf, 6th slide. (1 pt. for all)
Ex.) As for “IF/ID” pipeline register,
NPC (32 bits): next PC (PC+4)
IR (32 bits): instruction itself
(2) Answer the binary value of each field (you defined in (1)) in EX/MEM pipeline register when the “add” instruction in the following code exists in MEM stage. (1 pt. for all)

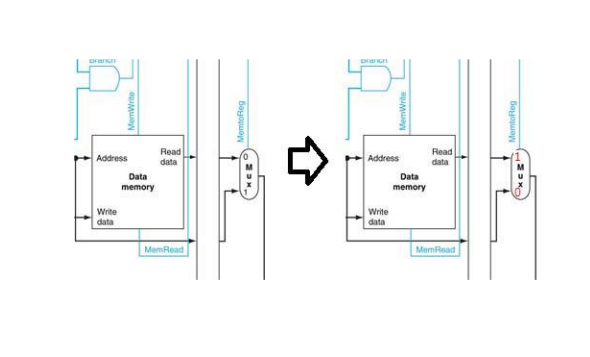
(3)What is “delayed branch” ? The answer must include the aim and the mechanism. (1 pt.)
The following code has loop structure. (Delayed branch is assumed.)

(1) If the instruction sequence is executed by the MIPS 5-stage, single issue pipeline, what is CPI ? Basically, it is supposed that one instruction takes 1-cycle to execute, except that data hazards by load instructions
generate 1-cycle bubble. (0.5 pt.)
(2)If the code sequence is restructured (without code scheduling) and executed by the MIPS static multiple issue (2 instructions issue), what is CPI ? Show a table like one in the 7th lecture slide(Lec7_e.pdf), page 6. (Both CPI value and the table are required.) (0.5 pt.)
(3) Apply code scheduling to the code sequence derived in (2) in order to decrease CPI. Show a code (table) after code scheduling, and CPI. (Both CPI value and the table are required.) (0.5 pt.)
(4) Apply loop unrolling (so that 4 iterations are packed into a loop body) and code scheduling with register renaming in order to obtain smaller CPI. Show a code (table) after unrolling and code scheduling, and CPI. (Both CPI value and the table are required.) (0.5 pt.)

更多代写:Cs代写 gmat线上代考 英国金融代写 Econometrics/Quantitative Economic(计量经济学)Essay代写 参考文献 cs计算机体系结构作业代做
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

CSCI-570 Analysis of Algorithms Practice Exam - 2 算法分析代写 True/False Problems 1. For every graph G and every maximum flow on G, there always exists an edge such that increasing the ...
View details
CSCI-UA.0480-009 midterm (47 points) 计算机网络代写 1. (3 points) What are the units of throughput, queueing delay, window size, capacity, RTT, and Bandwidth-Delay Product? Instructi...
View details
网络安全代写能提供哪些服务?留学生代写费用高吗? 网络安全代写 2022国内的代写已经是非常成熟的了,无论对于国内大学还是国外的留学生来说都可以满足很多的论文代写服务。尤其是国外的留学生在写作上存在...
View details
CSE 158/258: Homework 3 机器学习课业代做 Instructions These homework exercises are intended to help you get started on potential solutions to Assignment 1. We’ll work directly with the Instr...
View details