机器学习理论代写 机器学习作业代写 机器学习代写 作业代写
307ASSIGNMENT 机器学习理论代写 CHAPTER 4 Note that you should not be using aids such as mathexchange to solve these problems. Better to work on them alone, get stuck, CHAPTER 4 Note that y...
View detailsSearch the whole station
数据分析和机器学习代写 Question 1. [5 MARKS] Choose the most suitable option for each of the five parts (a)-(e) in the table below. Part (a) [1 mark] Under the
Choose the most suitable option for each of the five parts (a)-(e) in the table below.
| A / B / C / D | |
| Part (a) | |
| Part (b) | |
| Part (c) | |
| Part (d) | |
| Part (e) |
Under the assumption of simple universal hashing, which statement is more accurate for a hash table with 100,000 slots?
A) We almost certainly get a collision as soon as the table gets less than 92% empty.
B) We almost certainly get a collision as soon as the table gets 1% full.
C) It is slightly more likely to get a collision than not get a collision, in the next data insertion attempt as soon as the table is 6.3% full.
D) It is slightly less likely to get a collision than not get a collision, in the next data insertion attempt as soon as the table is 6.3% full.
Given a list, L1= [1, 2, 3, 4], which line of code does NOT do exactly the same things as the other three?
A) L2 = L1
B) L2 = L1[:]
C) L2 = list(L1)
D) L2 = L1[:2] + L1[2:]
Which of the following statements regarding K-Means clustering is false?
A) K-Means can be used to perform image compression.
B) The number of clusters can be determined based on the minimum squared distances.
C) The elbow point of the scree plot indicates the suitable value of the hyperparameter.
D) K-Means does not always converge to a global minimum.
If you were asked to apply a clustering algorithm to the following dataset so that each crescent is its own cluster. Which of the following option would work?
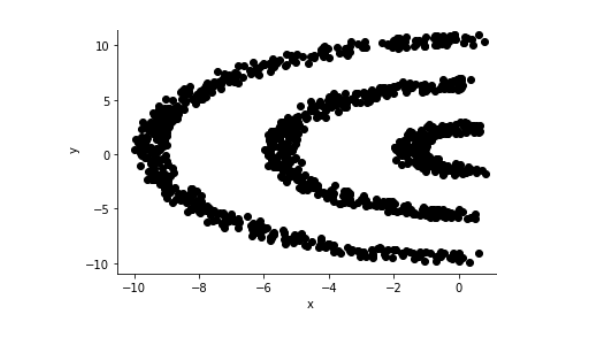
A) k-means clustering
B) agglomerative clustering
C) Gaussian mixture
D) all of the above
Given a system of linear equations in matrix form Ax = b. Which of the following matrices could you left multiply A such that it would multiply the first row by 5 and adds it to row2?
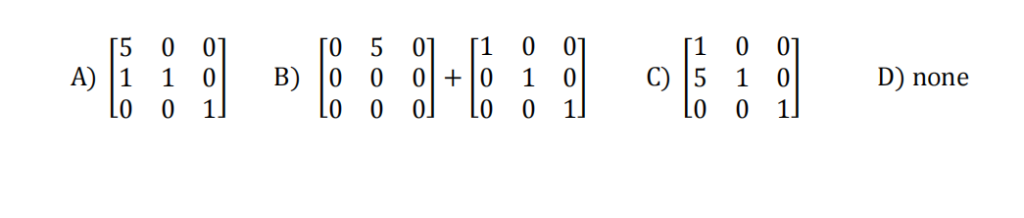
Consider a dataset of physiological measurements of elite athletes.
| Variable | Description |
| X1X2X3X4X5X6X7X8X9X10 | Skinfold thickness Grip strength Maximal vertical jump capacity Maximal lactate steady state (endurance) Maximum oxygen uptake (aerobic fitness) Mean corpuscalar hemoglobin count (resistance to and recovery from fatigue) Anaerobic power Maximum heart rate Muscle mass Muscle fatigue onset time |
A principal component analysis was performed yielding the following results.
Eigenvalues = [7.49 3.23 1.84 0.26 0.20 0.13 0.08 0.05 0.04 0.02 0.01]T
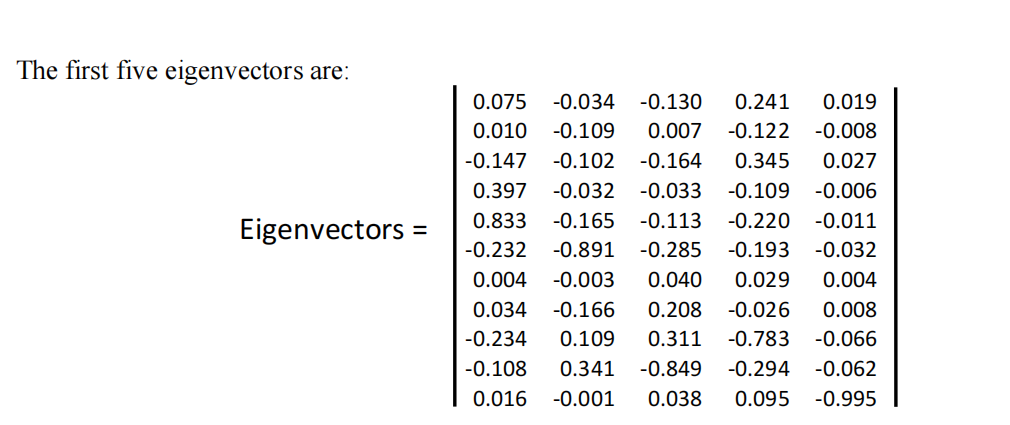
Part (a) [2 marks]
If we would like to capture 80% of the variance, what would you use as the new dimension? Justify your answer.
Part (b) [1 mark]
Which physiological measurements has the least importance in principal component 1? Which physiological measurements has the highest importance in principal component 2?
Part (c) [2 marks]
Given a sample x = [0.1 -0.3 0.4 -0.1 0.2 0.6 -0.2 0.5 -0.1 0.9 -0.1]T what would be its new coordinates using the first three principal components?
Part (d) [1 mark]
Knowing that the data has been standardized before conducting this PCA, how many singular values will be larger than 0.5 in the singular value decomposition of the same data?
Determine each of the five statements (a)-(e) as “True” or “False” in the table below.
| Statement | True / False |
| Part (a) | |
| Part (b) | |
| Part (c) | |
| Part (d) | |
| Part (e) |
Part (a) [1 mark] A suitable algorithm for sorting records in databases which are slightly out of order is quicksort because is typically faster than mergesort in practice.
Part (b) [1 mark] k-Nearest Neighbours and Decisions Trees can only be used for problems with discrete outcome variables.
Part (c) [1 mark] Inductive bias is a cause of machine learning algorithms having a higher test error than training error.
Part (d) [1 mark] Increase in recall always involves a decrease in the false negative rate regardless of the other parameters.
Part (e) [1 mark] Classifications made by decision trees do not depend on whether we apply StandardScaler to our training data or not.
The following diagram represents a system of buildings that are interconnected on the university campus. Your goal is to select a suitable sequence of potential locations (1 – 13) to construct cafes so that students can obtain a beverage and/or snack without having to traverse more than one edge. For example, a cafe at location 1 can be accessed by students in buildings 1, 2 and 3. The cost to construct a cafe is specified for each of the proposed locations.
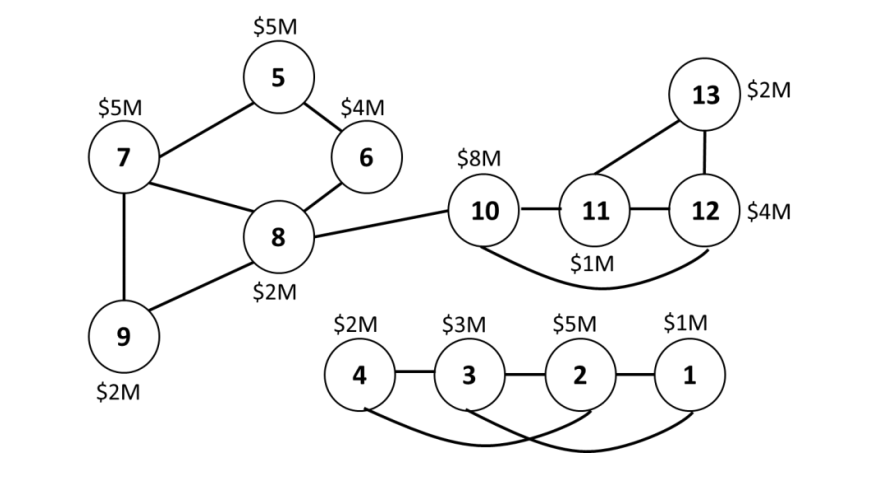
Using the greedy algorithm that you have learned in APS1070, find the most suitable sequence of locations to construct cafes and the total cost. Show all your work.
The following question pertains to a 2-layer artificial neural network used for multiclass classification. The network uses sigmoid activation functions on the hidden layer and on the output layer.
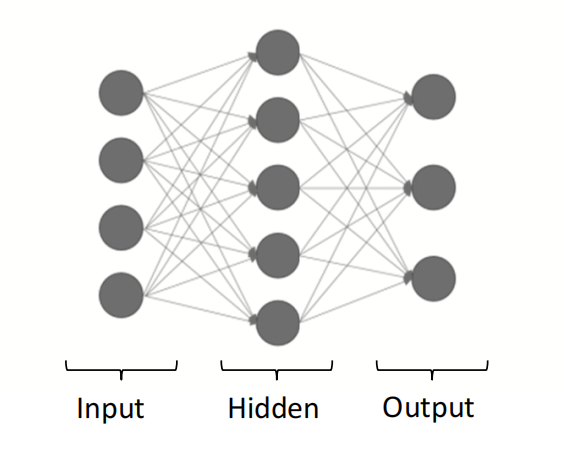
Part (a) [2 marks]
Write out the equations to perform the forward pass for the proposed neural network using vectorized notation.
Part (b) [2 marks]
Can this network learn nonlinearly separable decision boundaries? Explain why.
Part (c) [2 marks]
If we experience that the weight updates are too slow, what might have caused that and what change do you recommend to tackle this issue?
Part (a) [2 marks]
Compute for the singular value decomposition of matrix A below. Show all your workings.
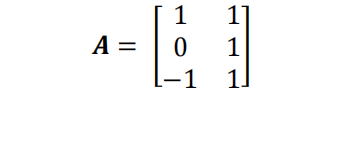
Part (b) [1 mark]
Compute ∑ for the singular value decomposition of matrix A below. Show all your workings.
Part (c) [2 marks]
Compute for the singular value decomposition of matrix A below. Show all your workings.
Part (d) [2 marks]
According to the singular value decomposition you computed, describe stage 1 of the
transformation of the following shape when transformed by A.
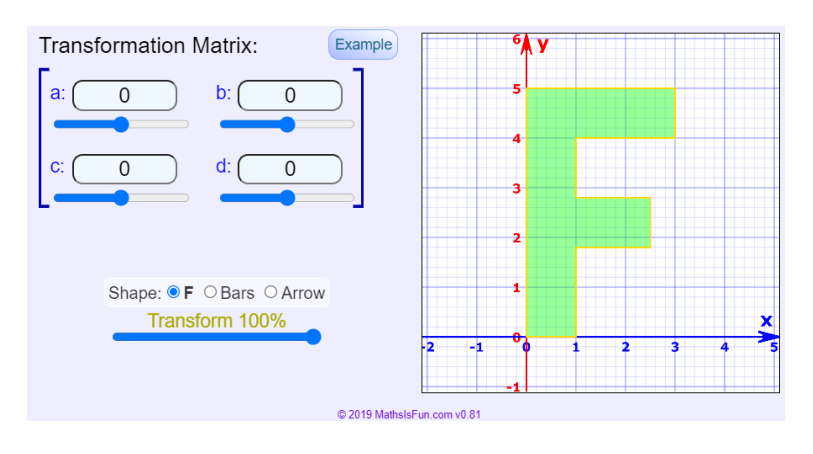
Part (e) [2 marks]
According to the singular value decomposition you computed, describe stage 2 of the
transformation of the same shape when transformed by A.
Part (a) [1 mark]
A hypercube with side length 1 in d dimensions is defined to be the set of points (x
1, x2, …, xd) such that 0 ≤ xj ≤ 1 for all j = 1, 2, …, d. The boundary of the hypercube is defined to be the set of all points such that there exists a j for which 0 ≤ xj ≤ 0.05 or 0.95 ≤ xj ≤ 1 (namely, the boundary is the set of all points that have at least one dimension in the most extreme 10% of possible values). What proportion of the points in a hypercube with d=50 are in the boundary?
Part (b) [2 marks]
Which machine learning concept is demonstrated by your observation in part (a)? Explain it in the context of your observation in part (a).
Part (c) [2 marks]
Which of the following methods deals more effectively with the concept from part (b)? Justify your answer.
• Generalized Linear Models
• Decision Trees
• Random Forests
• K-NN
• K-Means

更多代写:c++作业辅导 托福在家考试 英国Statistics统计学代考 Reflective Essay代写 Report代写推荐 大学论文例子
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

ASSIGNMENT 机器学习理论代写 CHAPTER 4 Note that you should not be using aids such as mathexchange to solve these problems. Better to work on them alone, get stuck, CHAPTER 4 Note that y...
View details
CS5487 Machine Learning Online Midterm 机器学习考试代考 Time: 2 hours 1. The following resources are allowed on the midterm: • You are allowed a cheat sheet that is one A4 page (single-sided...
View details
CSE 158/258, Fall 2021: Assignment 2 Web 挖掘和推荐系统代写 Instructions This is an open-ended assignment in which you are expected to write a detailed report documenting your results. Ins...
View details
MSCA 37014 Machine Learning Final Project (Replacing Assignment 4) 机器学习作业代写 Airbnb is interested in better understanding data relating to price of listings on their website. They ha...
View details