代写计量经济学课业 ECON7310代写 计量经济学作业代写
498ECON7310: Elements of Econometrics Research Project 3 代写计量经济学课业 Instruction Answer all questions following a similar format of the answers to your tutorial questions. When you use ...
View detailsSearch the whole station
代考计量经济 PART A – MULTIPLE CHOICE ANSWER ALL QUESTIONS ON THE MULTIPLE CHOICE QUESTIONS ANSWER SHEET EACH QUESTION IS WORTH 4 MARKS (TOTAL 48 MARKS)
Examination Duration: 120 minutes
Reading Time: 10 minutes
ANSWER ALL QUESTIONS ON THE MULTIPLE CHOICE QUESTIONS ANSWER
SHEET EACH QUESTION IS WORTH 4 MARKS (TOTAL 48 MARKS)
(a) will always be present as long as the regression R2 < 1.
(b) is always there but is negligible in almost all economic examples.
(c) exists if the omitted variable is correlated with the included regressor but is not a determinant of the dependent variable.
(d) exists if the omitted variable is correlated with the included regressor and is a determinant of the dependent variable.
(a) increase the regression R2 .
(b) make the variables of interest no longer correlated with the error term, once the control variables are held constant.
(c) reduce imperfect multicollinearity.
(d) reduce heteroskedasticity in the error term.
(a) use t-statistics for each hypothesis and reject the null hypothesis if all statistics exceed the critical values for their corresponding single hypotheses.
(b) use the F-statistic and reject all the hypotheses if the statistic exceeds the critical value.
(c) use t-statistics for each hypothesis and reject the null hypothesis once the statistic exceeds the critical value for a single hypothesis.
(d) use the F-statistics and reject at least one of the hypotheses if the statistic exceeds the critical value.
(a) a 1% change in X is associated with a β1% change in Y .
(b) a change in X by one unit is associated with a β1 change in Y .
(c) a change in X by one unit is associated with a 100 × β1% change in Y .
(d) a 1% change in X is associated with a change in Y of 0.01 × β1.
(a) is overcome by adding the squares of all explanatory variables.
(b) results in a type of omitted variable bias.
(c) is more serious in the case of homoskedasticity-only standard error.
(d) requires alternative estimation methods such as maximum likelihood.
(a) you just need to exclude one of the entity dummy variables to avoid perfect multicollinearity.
(b) all explanatory variables are exogenous.
(c) you must exclude one of the entity dummy variables and one of the time dummy variables for the OLS estimator to exist.
(d) the OLS estimator no longer exists.
(a) irrelevance of the regressor.
(b) simultaneous causality.
(c) omitted variables.
(d) errors in variables.
(a) that exogenous variables are determined inside the model and endogenous variables are determined outside the model.
(b) dependent on the sample size, i.e., for n sufficiently large, endogenous variables become exogenous.
(c) dependent on the distribution of the variables, i.e., when they are normally distributed, they are exogenous, otherwise they are endogenous.
(d) whether or not the variables are correlated with the error term.
(a) may have homoskedastic regression errors.
(b) allows the change in the predicted probability for a given change in X to be different for all different values of X.
(c) is the application of the multiple regression model with a continuous left-hand side variable and at least one binary variable as the regressors.
(d) can have predicted values greater than 1 or below 0.
(a) cannot be estimated since correlation does not imply causation.
(b) is typically estimated using the probit regression model.
(c) can be estimated using the “differences-in-differences” estimator.
(d) can be estimated by looking at the difference between the treatment and the control groups after the treatment has taken place.
(a) the time series is stationary.
(b) regression models estimated using past data can be used to forecast future values.
(c) historical relationships might not be reliable guides to the future.
(d) the joint distribution of (Yt+1, Yt+2, …, Yt+T ) does not depend on t, regardless of the value of T.
(a) current and lagged values of the error term.
(b) lags of the dependent variable, and lagged values of additional predictors.
(c) current and lagged values of the residuals.
(d) lags and leads of the dependent variable.
ANSWER ALL QUESTIONS IN THE BOOKLET PROVIDED
MARKS ARE AS SHOWN (TOTAL 52 MARKS)
Y = β0 + β1X1 + β2X2 + u (1)
We are interested in studying the causal effect of X2 on Y , i.e., β2.
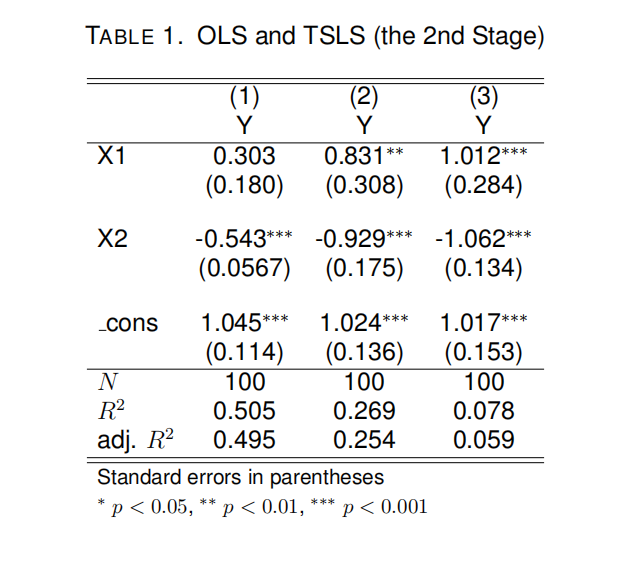
The OLS estimation results for (1) are reported in column (1) of Table 1. Write out the estimated regression equation along with standard errors and one measure of fit in a standard form. (2 marks)
If X2 were endogenous, which least squares assumption would be violated? What could be wrong with OLS if this assumption is indeed invalid? (3 marks)
We now estimate β2 using two-stage least squares (TSLS), instead of OLS. Z1 is one of our candidate instrumental variables (IV). What conditions must hold for Z1 to be a valid IV for X2? (4 marks)
Suppose Z1 is a valid IV for X2. We run a TSLS regression using Z1 and present the estimation results in column (2) of Table 1. Write out the estimated regression equation for the second-stage estimation. Is β2 exactly identified, over-identified, or under-identified? (3 marks)
We obtain the TSLS results in (d) using Stata’s ivregress command. What could be wrong if we run TSLS “manually” (i.e., use the regress command twice to replicate the TSLS procedure)? (2 marks)
How to determine if Z1 is a weak IV? Propose a procedure for testing the relevance of Z1. (4 marks)
Suppose we have another candidate IV, Z2. Name a test that can be used to test the exogeneity of Z2. (2 marks)
Now suppose both Z1 and Z2 are valid IV. The results for the TSLS using both Z1 and Z2 are reported in column (3) of Table 1. Using results in columns (2) and (3), how many IV do you want to use to estimate β2? Explain your answer. (2 marks)
Do citizens demand more democracy and political freedom as their incomes grow? That is, is democracy a normal good? We use a panel dataset to answer this question empirically. The dataset contains an index of political freedom/democracy (dem indit) for each country i in each year t, together with data on each country’s real GDP per capita (gdppcit).

We first fit the following (pooled) linear regression model to the data
Dem_indit = β0 + β1log(gdppcit) + uit
The OLS estimation results are reported in column (1) of Table 2. Explain what β1 measures. Interpret the estimate of β1. (3 marks)
Countries have different histories, social structures, and religions, etc. Unfortunately, we do not observe these factors in the data. We are worried that omitting these factors may cause omitted variable bias.
i. What conditions are to be met for these unobserved factors causing omitted variable bias? (2 marks)
ii. We think these unobserved factors vary across countries but plausibly vary little, or not at all, over time. Therefore, we re-estimate the regression in (a) using fixed effects (FE) method (“entity-demeaned” OLS). Write out the estimation equation for the FE estimation. (2 marks)
iii. The FE estimation results are summarized in column (2) of Table 2. Do you reject the null hypothesis H0: β1 = 0 at the 1% significance level? Explain your answer. (2 marks)
iv. Compare the FE and OLS results. Do you think the regression in (a) suffers from omitted variable bias? Explain your answer. (2 marks)
When running the FE estimation, we use the vce(cluster country)option. Briefly explain what this option is for, and what could be wrong if it is not used. (2 marks)
In column (3) of Table 2, we report estimation results for an FE model controlling year dummies. Briefly explain the reason(s) for including these dummy variables in the regression. (2 marks)
We use data to study the labor force participation of married women. The dependent variable is inlf, which takes on a value of 1 if a woman is in the labor force, and 0 otherwise. The variables we use to explain inlf are as follows:
• nwifeinc: husband’s annual income in thousands.
• educ: years of schooling.
• exper: work experience in years.
• expersq: exper2.
• age: woman’s age in years.
• kidslt6: number of kids < 6 years old.
We estimate linear probability, probit, and logit models for inlf using the explanatory variables listed above. The estimation results are summarized in columns (1)-(3) of Table 3, respectively.
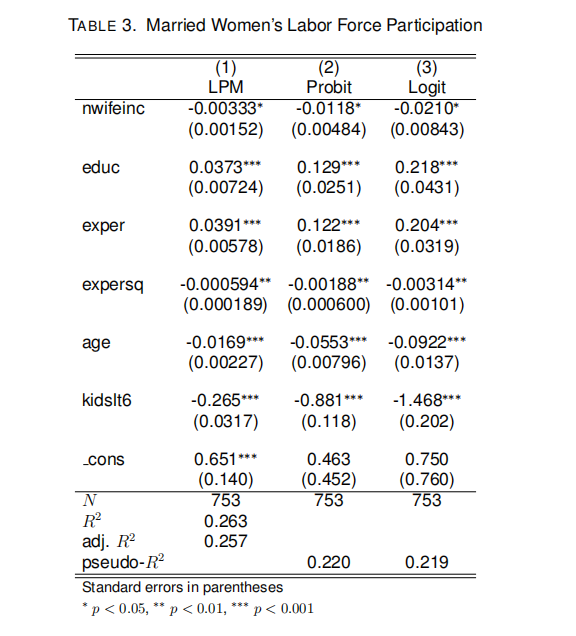
Interpret the estimate of the coefficient on educ using the estimation results of the linear probability model (LPM). (3 marks)
(b) Interpret the estimate of the coefficient on educ using the probit results. (3 marks)
(c) Kate is married and 28 years old. She has a college degree (educ = 16), 3 years of work experience, and a four-year-old daughter. Her husband’s annual income is $20,000 (nwifeinc = 20). Using the LPM regression results, what is the effect of a hypothetical change in Kate’s experience from 3 to 4 on the probability of her being in the labor force? [Hint: For simplicity, here we assume that the values of other explanatory variables (e.g., age) are unchanged.] (3 marks)
(d) Repeat (c) using the logit regression. (3 marks)
(e) What is the pseudo-R2 of the probit regression? How do you interpret pseudo-R2? (3 marks)


更多代写:R代写 托福在家考试作弊 英国Financial网课代写 problem solution essay写作步骤 Report代写价格 代写计量经济学课业
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

ECON7310: Elements of Econometrics Research Project 3 代写计量经济学课业 Instruction Answer all questions following a similar format of the answers to your tutorial questions. When you use ...
View details
ECON 3101 - Intermediate Microeconomics Section: Game Theory 中级微观经济学代考 This section, Game Theory, has 3 questions. Choose two of them to answer. Note, the questions you decide to c...
View details
ECON7310: Elements of Econometrics 计量经济作业代写 Instruction Answer all questions following a similar format of the answers to your tutorial questions. When you use R to conduct empirical ...
View details
ECON3006/4437/8037: Financial Economics Final Exam 金融经济学代考 • 100%=25 points (30 points for students in 8037) reading/scanning/uploading time: 15 minutes writing time: 180 minutes (19...
View details