大数据作业代写 Big Data代写 大数据代写 数据库代写
608Big Data 大数据作业代写 Question 1 20 Marks A. Outline the steps that a read request goes through, starting when a client opens a file on HDFS (given a pathname) Question 1 20 Marks ...
View detailsSearch the whole station
数据库管理和编程代写 Tasks to be undertaken: Here is a summary of the tasks for this coursework: 1. Personalise and load data in collections 2. Query the collections
Here is a summary of the tasks for this coursework:
1. Personalise and load data in collections
2. Query the collections (queries Q1 to Q4).
3. Implement and Explain Index for the database (E1).
4. Re-design the database (D1).
5. Weekly Journals
1. You are required to upload your answers to the questions into Turnitin on Blackboard as one file (DOCX only).
2. All questions and answers must be labelled with section number and where necessary, the question number
3. Add your P number to your filename. Your file must be in a readable format so the NoSQL code in plain text (Q1 to Q4, E1 and D1) can be copied and executed from it (in DOCX format).
1. Mark totals are shown alongside each question. Your tutor will need to able to execute your NoSQL code in MongoDB to check for correctness.
2. Marks will be awarded for correctness and presentation. Marks will typically be deducted if information is erroneous, missing, irrelevant or difficult to ascertain.
3. Marks can also be deducted if the answer is particularly inefficient. Therefore, partial marks are available if an answer is partially correct or partially presented.
4. There is often more than one way to answer a question and so it is possible to gain full marks for an answer even if it is different from the markers’ specimen set of answers.
5. However, if these answers do not follow the examples and exercises taught on the module they may be inferior in some way and so consequently marks may be deducted. Note that some questions hint at the most appropriate method to use.
6. Read the full specification enclosed below for the details.
This is an individual assignment, which gives you an opportunity to demonstrate your knowledge of NoSQL and your ability to implement, query and design a MongoDB document database. You will be awarded marks for what is achieved. This assignment is worth 50% of the overall module mark.
Amazon.com, commonly known as Amazon, is an American e-commerce and cloud computing company that was founded in 1994. It is the largest internet-based retailer in the world by total sales and market capitalization. It sells an enormous variety of products and stores huge datasets which includes reviews (ratings, text, helpfulness votes etc.) and product metadata (descriptions, category information, price, brand, and image features etc.).
A subset of Amazon data has been selected for this coursework. The product and review data is based on some software spanning October 1999 to July 2018.
Permission was granted to use the data for this coursework from the following source: http://jmcauley.ucsd.edu/data/amazon/ on condition that the authors’ research papers are referenced (He & McAuley 2016), (McAuley et al. 2015). It is not necessary to read these papers to complete this coursework.
1.Download the two CSV files from Blackboard; they are called:
a. software.csv
b. reviews.csv
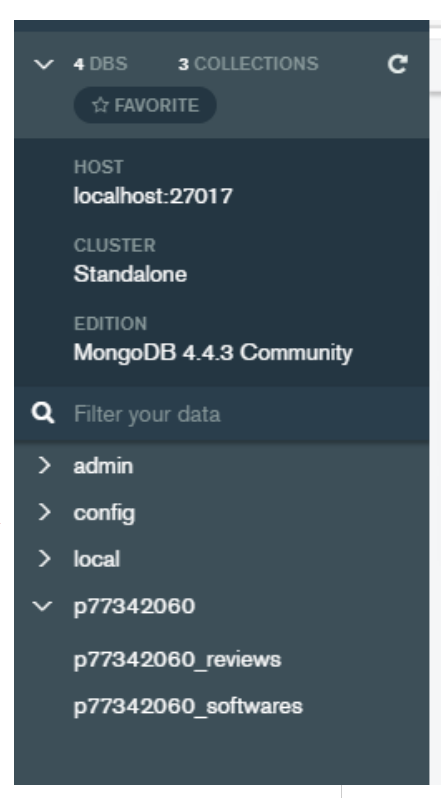
2.Create a database in MongoDB Compass with your Pnumber as Database name
3.Then create and import the data into two new MongoDB collections with the collection names prefixed with your own P Number
Look at the image here
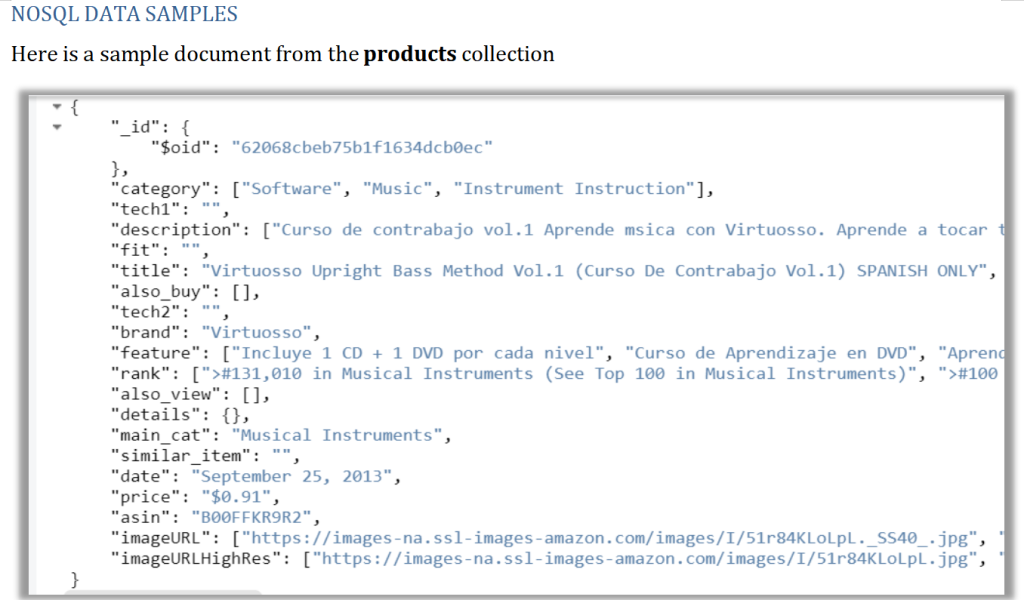
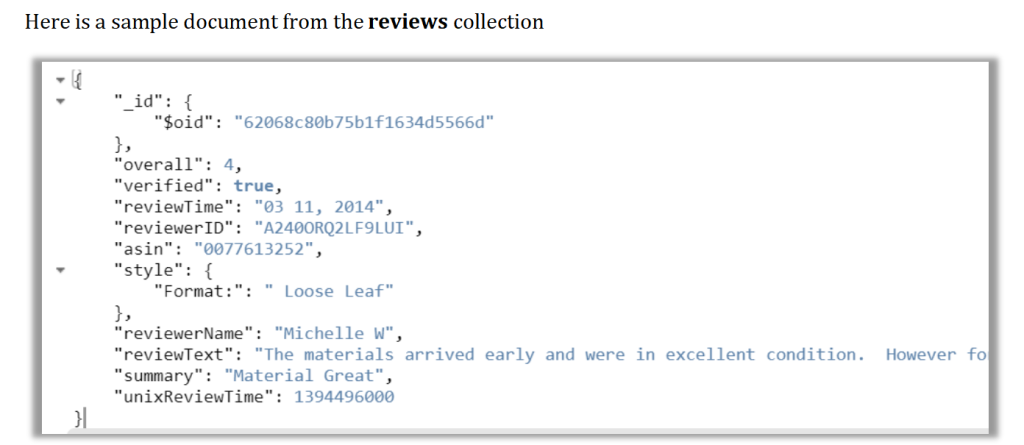
Here is description of some fields from the collections
| Field | Description |
| asin | ID of the product, e.g. B00005BHKS |
| category | list of categories the product belongs to |
| description | description of product |
| main_cat | main category of product |
| price | price in US dollars (at time of crawl) |
| imageURL | url of the product image |
| reviewerID | ID of the reviewer, e.g. A1RVTBD2QZ8TQ8 |
| reviewerName | name of the reviewer |
| overall | rating of the product |
| unixReviewTime | time of the review (unix time in seconds) |
Have a quick look at the collections on MongoDB Compass, you will realise that some of the data was only scrapped from the internet and does not have complete or useful information that we need for this coursework. This missing information may include:
You are to clean the collections as follows:
1.Using Aggregation pipeline, create a new collection named p77342060_softwares_cthat satisfies the following conditions
a)Price field is valid (the string provided is of length >= 4 and length <= 8) and is converted to double [4 marks]
b)Date field is valid (the string provided is of length >= 10) [4 marks]
Hints:
2.Create a new collection p77342060_reviews_cthat contains only reviews that matches a product from p77342060_softwares_c [4 marks]
Hints:
Write the following queries (Q1 to Q4) against the Amazon products and reviews collections that you personalised and loaded into MongoDB. For each query, submit the MongoDB command in plain text, AND present it with its results as a screenshot showing the command and the documents returned. For example:
//Q10. Find the details of the product identified as ” B001KTEBOG “.
db.p77342060_softwares.find({asin:”B001KTEBOG”})
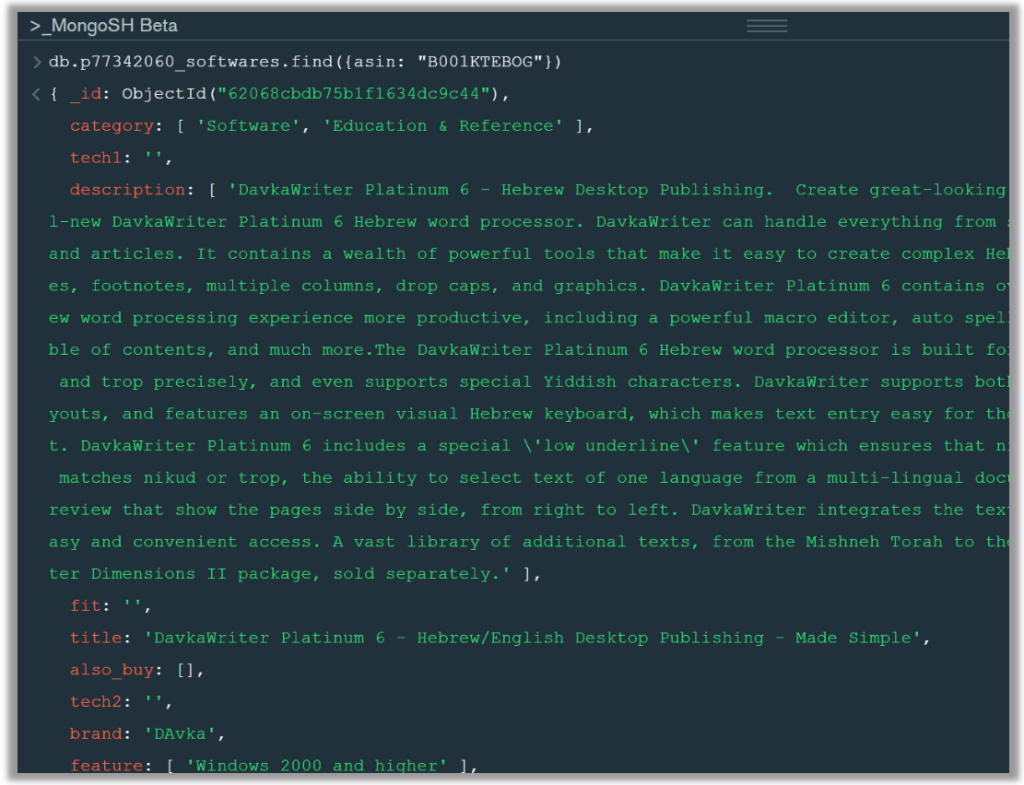
If a lot of documents are returned, show the first set of documents that are displayed. Ensure that what is displayed answers the requirements and demonstrates that the query is correct. You must do this to gain all the marks available for a question.
Q1. Find all details of products that are priced at between $7.99 or $59.99. [3 marks]
Q2. List all the reviewers who have written at least 3 reviews. Show the reviewer ID, reviewer name and the number of reviews for each one. List the names of reviewers in alphabetical order. [3 marks]
(Hint: it is possible to solve using aggregate pipeline method).
Q3. Find the average overall rating by the reviewer identified as “A3RMR8A0G2YSZ” by using aggregate pipelining method. [3 marks]
Q4. Using both collections, find the title and price of products reviewed by the reviewer identified by “A3RMR8A0G2YSZ”. No other product details are required. [3 marks]
1.Identify the chosen query and explain/justify your choice of index. Why do you think indexing could improve the query [2 marks]
2.Implement one index that would improve the querying of the database based on one or more of the queries (Q1-Q4). [2 marks]
3.Present the execution plan of the selected query before the index and after the index has been created. Compare and discuss the execution plans to support your choice and summarise your findings. [4 marks]
Write code in MongoDB to automatically embed the details of reviews from the reviews collection with their corresponding product in the product collection.
Therefore, the products collection will contain both the product data and review data in a single collection of products. This requires the following tasks:
1.Make new copies of the products and reviews collections and give them new names. Show screenshot showing all the collections [1 marks]
2.Embed all the reviews into their corresponding product using the new collections. [5 marks]
3.To verify that the changes to the new products collection were successful, display the title and reviews of the product identified as “1495016897”. [1 marks]
4.Note that there is no longer a need to reference the product ID inside each review now that it is part of the product. Show that this is removed [1 marks]
All tasks 1-4 must each be fully automated by writing code. Note that task (2) may take many seconds or minutes to execute depending on the machine.
1.A list of Week 02 to Week 06 Journals’ submission status
a. Week 01 – Submitted
b. Week 02 – Late submission due to …..
c. Week 03 – No submission
DELIVERABLES
2.You are required to upload your answers to the questions into Turnitin on Blackboard as one file.
3.All questions and answers must be labelled with their capital letter and number (i.e. Q1 to Q4, E1 and D1). Add your P number to your filename.
4.Your file must be in a readable format so the NoSQL code in plain text (Q1 to Q4, E1 and D1) can be copied and executed from it.
5.In Turnitin, press both the Upload button and the Confirm button to submit your file and receive a receipt.
1.This is an individual assignment. Do not negotiate with others to clarify what is required. By uploading your work to Turnitin in Blackboard you will be declaring that the work you submit is your own and not plagiarised in any way.
2.Tutors are prepared to offer help with the part of the assignment where there is clear evidence that you have made a substantial attempt but have become stuck.
3.Mark totals are shown alongside each question. Your tutor will need to able to execute your NoSQL code in MongoSH to check for correctness. Marks will be awarded for correctness and presentation.
4.Marks will typically be deducted if information is erroneous, missing, irrelevant or difficult to ascertain. Marks can also be deducted if the answer is particularly inefficient. Therefore, partial marks are available if an answer is partially correct or partially presented.
5.There is often more than one way to answer a question and so it is possible to gain full marks for an answer even if it is different from the markers’ specimen set of answers. However, if these answers do not follow the examples and exercises taught on the module, they may be inferior in some way and so consequently marks may be deducted. Note that some questions hint at the most appropriate method to use.
He, J. McAuley. “Modeling the visual evolution of fashion trends with one-class collaborative filtering”. WWW, 2016.
McAuley, C. Targett, J. Shi, “A. van den Hengel. Image-based recommendations on styles and substitutes”. SIGIR, 2015.

更多代写:code代写机构 托福作弊被抓 英国Biology网课代考 Citation methods essay代写 Book Summary写作 文章修改
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

Big Data 大数据作业代写 Question 1 20 Marks A. Outline the steps that a read request goes through, starting when a client opens a file on HDFS (given a pathname) Question 1 20 Marks ...
View details
CPSC 437/537 Practice questions for chapter 17, 18, and 19 数据库考试代考 Please use it to answer questions 1 and 2. 1. Is this schedule conflict serializable? a. Yes b. No c. Not sure 2. Whic...
View details