金融大数据分析代写 FIN 510代写 R语言代写 大数据分析代写
182FIN 510 Big Data Analytics in Finance Lab 4: Data Exploration 金融大数据分析代写 Summarizing Data on Firm Fundamentals The file firm.csv containsfirm fundamental variables, including total ...
View detailsSearch the whole station
大数据分析考试代考 This exam will be administered over 80 minutes, and it is worth 80 total points. You should budget at most 1 minute per point on average.
_____________________________________
This exam will be administered over 80 minutes, and it is worth 80 total points. You should budget at most 1 minute per point on average. A single “cheat sheet” is allowed, and otherwise the exam is closed-book, closed-devices, closed-notes.
Your name:
_________________________________________________________
Your PennKey (Penn email ID) for disambiguation:
________________________________
Please sign: I understand and agree to follow Penn’s code of academic integrity in taking this exam.
__________________________________________________________
For the following multiple-choice questions, please select the single best answer. Each is worth 3 points.
If we find multicollinearity in our data and are using regression, what can we do?
a. apply PCA to map the data to a new subspace
b. use regularization
c. drop some of the correlated features
d. all of the above
A random forest is most similar to which type of ensemble method?
a. stacking
b. bagging
c. boosting
d. logging
What components do we need to perform a gradient descent operation?
a. weights and input, cost function, error, step size
b. weights and input, error, step size
c. weights and input, derivative of cost function, error, step size
d. weights and input, derivative cost function, error
If you spot many more negative than positive instances in your training data, you can:
a. up-sample the positive instances
b. down-sample the positive instances
c. up-sample the negative instances
d. add random data
When performing (ordinary least-squares without regularization) linear regression, we need to be careful about:
a. multicollinearity
b. scale
c. order in which the data instances appear
d. balance between two classes
In a CNN, which types of layers have associated weights?
a. convolution
b. pooling
c. dense
d. convolution and dense only
e. all of the above
What is a local receptive field?
a. a technique that converts from color to grayscale images
b. a sliding window over an image, connected to a single activation unit
c. a type of activation function
d. a mechanism for back-propagation
High-level distributed stream processing systems can only join stream data that is (choose the best answer):
a. Infinite
b. Static
c. Dynamic
d. within a window
e. Sharding doesn’t produce speedup.
Stream processing and message passing systems are similar in that the programmer:
a. has to handle issues in which data goes out of order
b. writes callback functions
c. does microbatching
d. writes computations in SQL
When downsampling time-varying data to a lower frequency, we should expect to:
a. average multiple samples
b. interpolate a new value between existing samples
c. insert null values
d. pad with copies of an existing value
What types of data might be suitable to archive in a data lake (choose the best answer):
a. JSON data
b. tabular data
c. text files
d. PDFs
e. all of the above
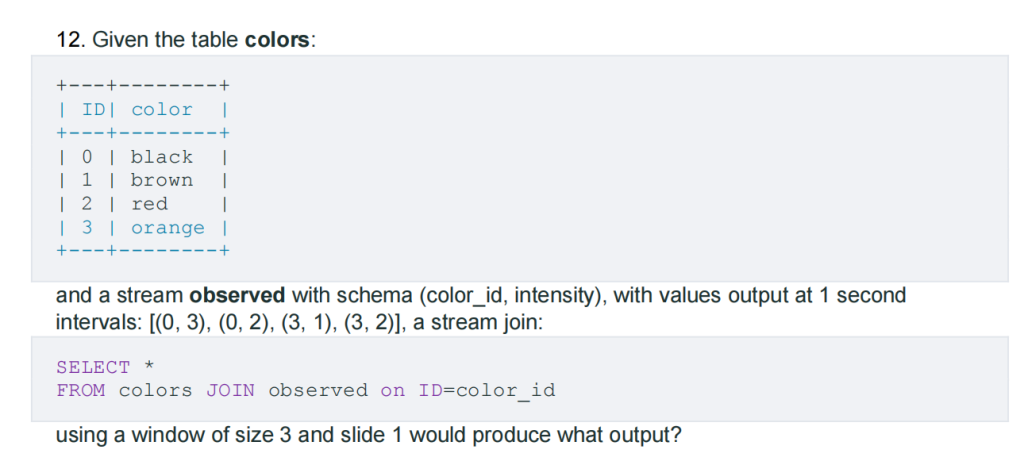
a. (0, black, 0, 2), (3, orange, 3, 2)
b. (0, black, 0, 3), (0, black, 0, 2), (3, orange, 3, 1), (3, orange, 3, 2)
c. (0, black, 0, 3), (3, orange, 3, 1)
d. no output
In a distributed computing environment, whether among servers, Spark cluster nodes, or distributed mxnet cluster nodes — as we increase the number of nodes, the biggest bottleneck to performance is ultimately:
a. coordination and synchronization
b. data size
c. dimensionality
d. the lack of GPUs
Operational DBMSs often are tuned for:
a. machine learning workloads
b. aggregation queries
c. transactional updates
d. data warehouses
Please give brief answers inside the provided area.
15.As part of a company project, you create a visualization over big data collected from the web. List 4 of the types of information you would need to capture, to have enough information to reconstruct (and thus allow someone else to verify) your visualization? (8 points)
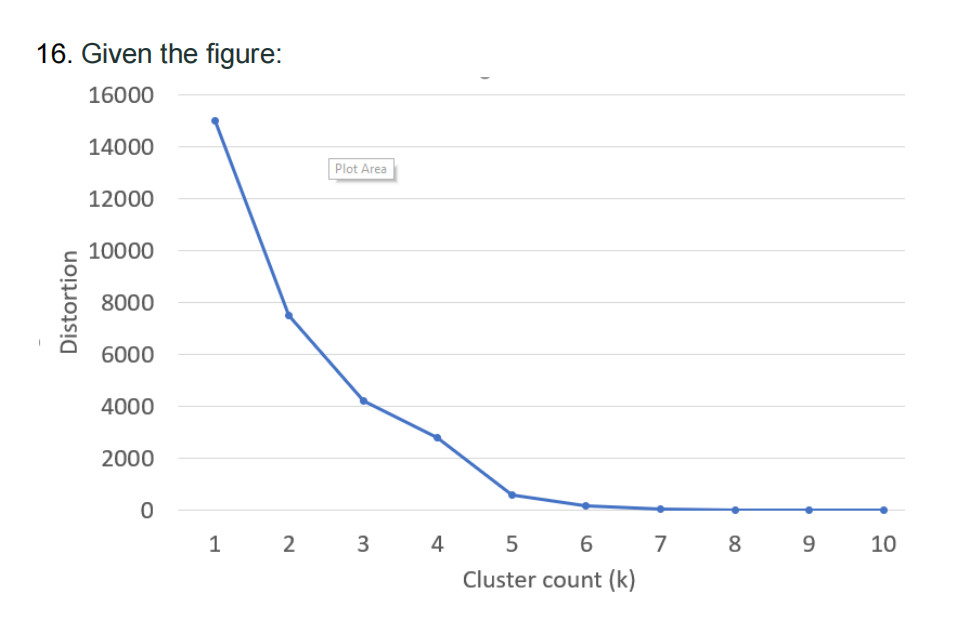
17.You should select which value for cluster coefficient k? (5 points)
A decision tree greedily determines the attribute on which to split by maximizing what measure? (5 points)
Each question is worth 10 points.
18.Suppose you have an input dataset with labels, and you wish to train a logistic regression classifier on this. You’ll be using ridge regularization.
Outline the “best practice” steps you would take to prepare the training data and to train the classifier. What do you check for, what data transformations should you apply, etc.
19.Suppose you are building a computer vision algorithm for a Jurassic Park-themed
amusement park. Explain the steps involved in taking a convolutional neural network trained on ImageNet and using domain adaptation to train it to recognize carnivorous dinosaurs, versus herbivorous ones. (Assume you have access to many labeled dinosaur images.)

(Image copyright Prime 1 Studio.)

更多代写:C++代考推荐 duolingo代考 英国bio生物学网课代上价格 ECO essay代写 Dissertation学位论文代写 如何写论文摘要
合作平台:essay代写 论文代写 写手招聘 英国留学生代写

FIN 510 Big Data Analytics in Finance Lab 4: Data Exploration 金融大数据分析代写 Summarizing Data on Firm Fundamentals The file firm.csv containsfirm fundamental variables, including total ...
View details